
わぁぁ、ロボ部のロゴがなんとも言えない凄み画像になってしまった。ロボ部イラスト仮担当tawagoです。
まさに悪夢、Googleの人工知能「DeepDream」でムービーを作成したらとんでもないことに
とかいうタイトルなどで一躍有名になりました、GoogleのDeep Dream。
巷で噂のDeep Learningの分野ですね。大量のデータをもとにホニャホニャ…
もちろんロボ部でもやってみました!
なにやらイテレーションという同じ画像を何回もDeepDreamすると面白いというのも聞きつけまして。えぇ、やりましたよ、実験を。2週間かかりました。
こんな感じです。どーん!(gifアニメ)

チャート図はこちら
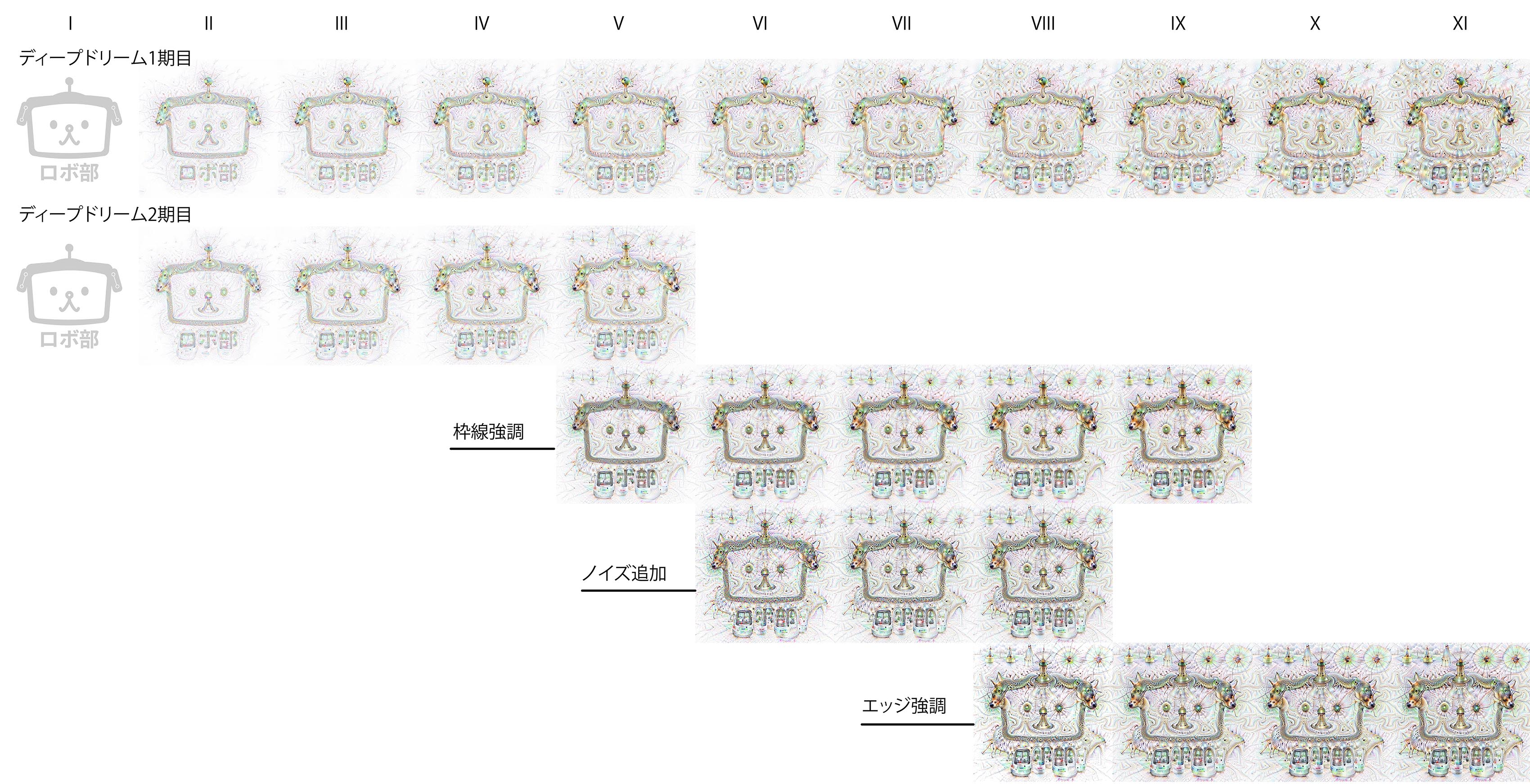
結果比較

新規で始めるたびに違うものが出現したりしなかったり。
どうやらランダムノイズがあった方が色味が増すみたいですね。禍々しい…
こんな感じでGoogleがこないだ公開した人工ニューラルネットワーク、Deep Dreamさんにお好きな画像を渡すと勝手に追加のお絵描きされてしまうんですが。
なんかやたらと動物が出現してるのでなんでかなー、と思って調べてたらGoogle Research Blogに詳しい説明が書いてありました。
Inceptionism: Going Deeper into Neural Networks
画像認識や音声認識に飛躍的発展をもたらしたニューラルネットワークは、よく知られた数方程式に基づいた便利なツールですが、僕達はいくつかのモデルがうまくいき、他はうまくいかない理由について驚くほど理解をしていなかったみたい。なのでネットワークに使われているシンプルな技術をちらっと覗いてみましょー!
まずは人工ニューラルに何百万ものサンプルを与えます。私たちが求めている水準が出来上がるまでバックプロパゲーションで徐々にパラメーターを調整をします。
ここでネットワークは10〜30程度の層を人工ニューロンとして作り上げるのですが、各画像は最初の層に入れられ、最終的なアウトプットを出す層にたどり着くまで、次の層へ次の層へと渡されていきます。このアウトプット層から「これはロボの画像だ!」などとネットワークの”お返事”が返ってくるのです。
さてさて、ここからが本番になってきます。このネットワーク内の各層で何が起こっているのか?を理解するのが非常に重要なんです。初期学習をした各層達は「これは何の画像か」という決定が最終層から下されるまで、漸進的により高い特徴を抽出していくようになります。例えば、最初の層はエッジや直線などに注視し、中間層あたりでドアや葉っぱなど基本的な形や要素などを探し始めます。最後の方の層達がこれらを組み立てることによって、全体の解釈が複雑に構成されたビルだったり木だったりとして判断されます。そこで、このネットワークを逆に利用してインプットした画像を特徴的な解釈で拡大誇張してもらうと、中で一体何が起きているのかが分かるようになるんです。
ネットワークにどのような画像が”バナナ”なのか?と聞いたとしましょう。完全にランダムなノイズ画像でスタートすると、少しずつ微調整をしながらニューラルネットワークが思う”バナナ”になります。 何も聞かない場合はそこまでうまくいかないのですが、事前確率のような制限があると、ニューラルの持つ画像に確率的に近くなるように隣り合うピクセルを直していくんです。

実はここで面白い驚きがありまして、様々なものを区別するよう学習させたニューラルネットは、画像を生成する上でもある程度の情報が必要みたいです。他の層の例も見てもらうと分かりやすいかも。

なんでこれが重要なのか? 僕達はニューラルネットワークに学んで欲しい沢山の画像を単純に与えただけで、後はその中から勝手に基礎となる部分を学習してくれることを期待しました。(例えばフォークだったら2〜4つの歯があるとか、サイズ・形・配色・向きなどは関係ないなど) だけどネットワークが正しく学んでくれたことを確認するにはどうしたらいいんでしょうか? 今回の実験が、ネットワーク内のモノに対する描写を知る手助けをしてくれます。幾つかのケースで明らかになったこととして、ニューラルネットワークは僕達が想像していないものを抽出していました。例としてダンベルについての描写はこんなものでした。

ここに写ってるダンベル自体はまぁまぁですね。でも、どの画像も重量挙げ選手が持ち上げているようなものが写っていませんし、かすかに腕のようなものが見えます。このケースではネットワークは正しい特徴の抽出に失敗してしまいました。もしかしたら与えた画像群の中に腕で持ち上げている以外のダンベル画像がなかったのかもしれません。このように、ニューラルネットワークによる画像生成は僕達の理解を深めてくれるのです。
ネットワークに強調して欲しい要素を正確に規定をする代わりに、ネットワーク自身に判断を任せることもできます。任意の画像や写真を与え、ネットワークに解析させます。そしてネットワークの持つ各層はそれぞれ異なるレベルの抽象性を持っているため、その中の一つの層を誇張するようにしてあげると、層によって複雑な特徴が生成されるのです。下層はエッジや向きに敏感なため、斜線や装飾のようなパターンを生成します。


仮に上級層を選ぶと、画像の中からより洗練された特徴を同定するため、複雑なものや時にはオブジェクトそのものが現れたりします。何度も言いますが、すでにある画像をニューラルネットワークに渡すだけなんですよ!? そしてネットワークに尋ねるのです、『君に見えるものどんなものでもいいから、それをもっと出してくれる?』と。これがフィードバックのループを作ることになり、もし”雲”がほんの僅かでも”鳥”に見えるならば、ネットワークがその部分をより鳥に見えるようにしてしまうのです。繰り返すごとに鳥が強調されていくため、鮮明に写った鳥が現れるまでループが続きます。まるでどこからともなく鳥が現れたかのように。

結果は非常に興味がそそられるものでした。比較的シンプルなニューラルネットワークでも拡大解釈が可能で、子供が雲を眺めて様々な形を見つけて遊んでいる様ですね。このネットワークは主に動物の学習をさせたため、解釈する形が自然と動物になっています。それでもデータはより高い抽象性の中で保管されているため、出力結果は学習したものを混ぜ合わせたような興味深い形をしています。。

もちろん、雲以外の画像でもこれはできます。特徴によってバイアスがかかるため、結果は画像のタイプによってかなり異なりました。水平線はタワーや仏塔で埋まりますし、岩や木などは建物に、葉っぱなどには鳥や昆虫などなど。

この技術は定性的な抽象度という観点を僕達に与えてくれました。ネットワークのどの層が画像解析でアクティブになったかが分かるのです。ニューラルネットワークの構造に関した”インセプショニズム”とでもいいましょうか。
さらに画像が見たい人はこちら
更なる深みへ: Iterations
もし、このアルゴリズムを反復的に適用し各処理毎に少しづつ拡大していくとネットワークが知っていることが探求され、僕達はエンドレスに新しい表現に辿り着くことを発見した。結果が純粋にニューラルネットワークのものとするために、ランダムなノイズ画像から始めたところ、このような画像となった。

以上がGoogleブログの意訳なんですが。
いやー。楽しいですね、これ。
自分の画像をDeep Dreamで試してみたい方はこちらからできますよっ。
http://psychic-vr-lab.com/deepdream/
人間の”何かを見ると何かを思い出す”というのは、このまさにニューラルネットワークの仕組みなんでしょうなぁ。
夏の匂いや音を感じると、青春時代を思い出しますよね。ふわぁ〜〜〜